近日,国际学术会议CVPR 2026论文接收结果公布,数据科学与人工智能研究院多篇论文被录用。CVPR全称为IEEE/CVF Conference on Computer Vision and Pattern Recognition(计算机视觉与模式识别会议),被认为是深度学习领域的顶级国际会议之一,与ICCV、ECCV并称为计算机视觉领域三大顶会。CVPR 2026将于2026年6月3日-7日在美国科罗拉多州丹佛市举行,会议将呈现和发布深度学习领域前沿研究成果。
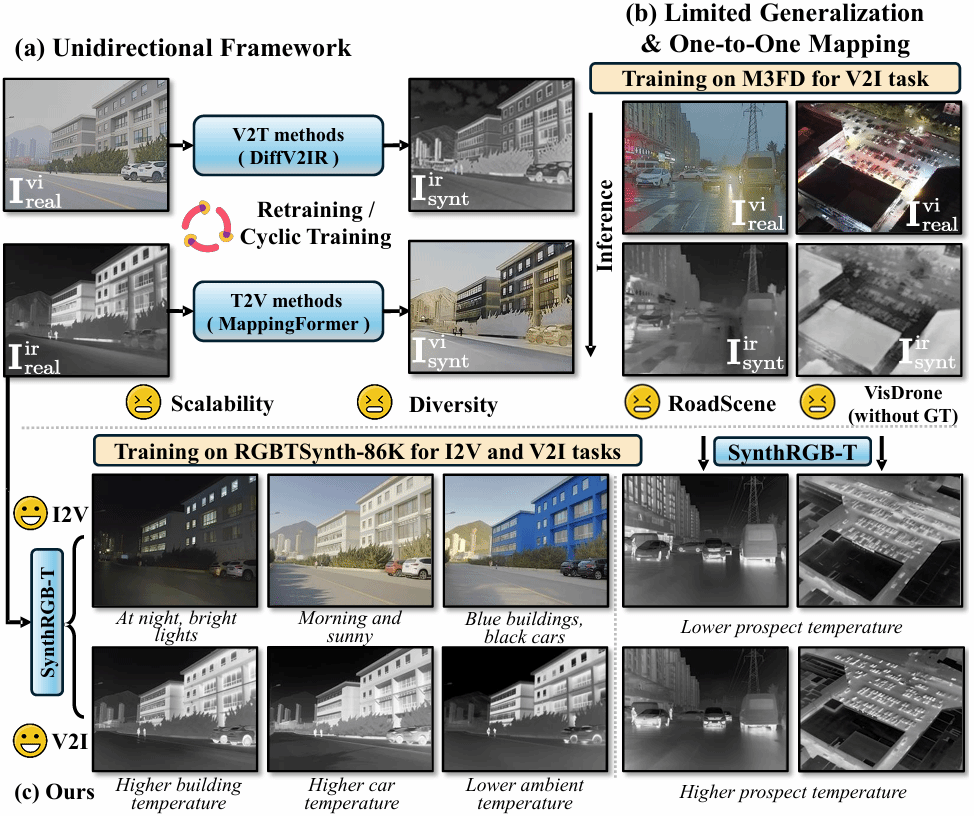
论文题目:SynthRGB-T: Language-Vision Guided Image Translation for Diversity Synthesis
第一作者:丁健刚(长安大学信息工程学院)
通讯作者:李伟(长安大学数据科学与人工智能研究院)
论文概述:弥合红外图像与可见光图像之间的模态差异,对于实现跨模态理解及丰富多模态基准数据具有重要意义。然而,现有研究方法多局限于一对一映射范式,且通常仅在单向或封闭场景中进行评估,难以满足复杂开放环境下的多样化需求。针对上述问题,论文将图像转换过程创新性地表述为一种由视觉与语言共同引导的去噪扩散过程。通过引入开放世界知识,实现了可控的双向图像翻译。此外,所提出的 SynthRGB-T 模型能够合成多样性强且高保真度的数据样本,显著拓展了多模态数据资源的规模与丰富度,为多模态领域后续研究提供了有力支撑。
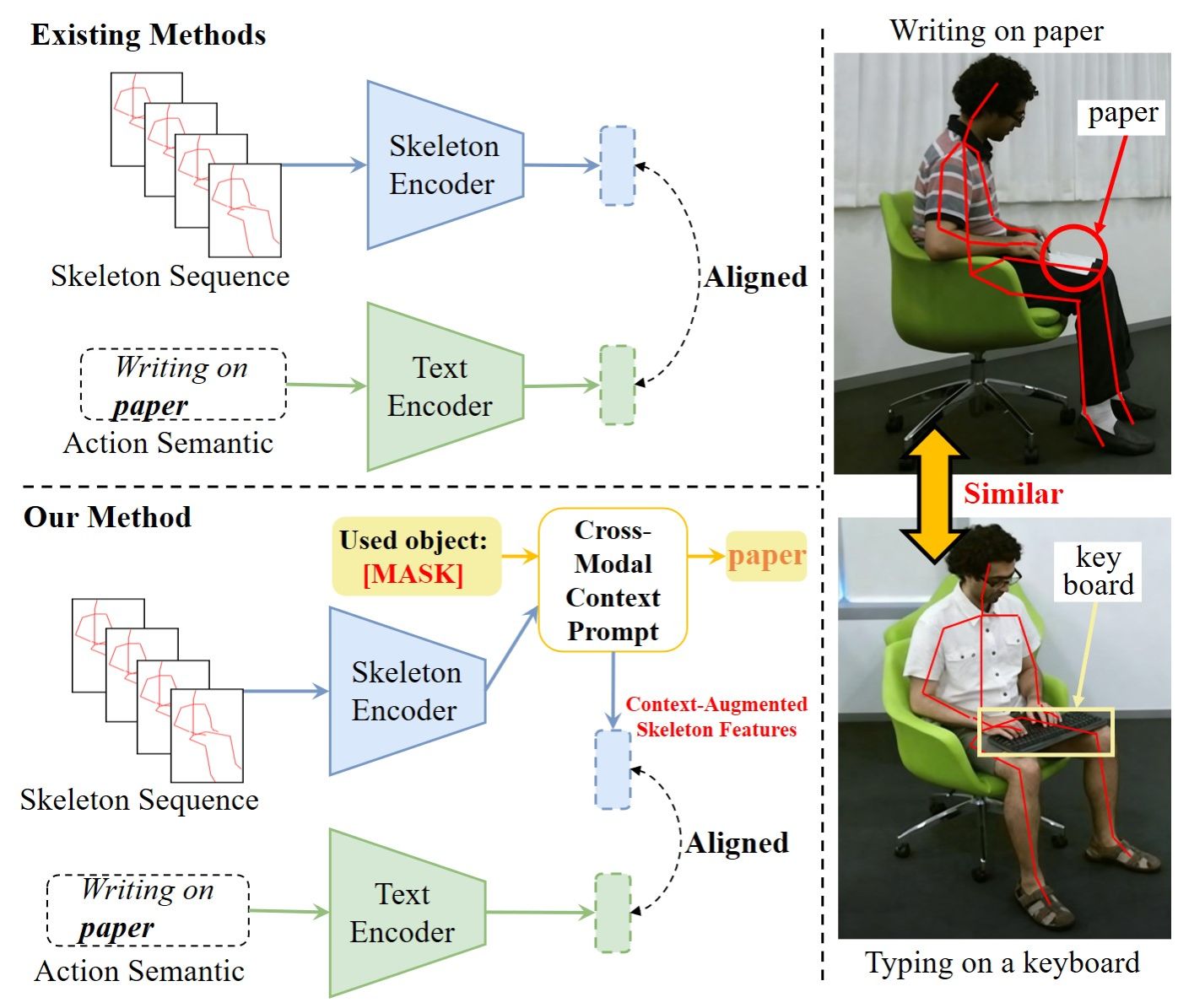
论文题目:SkeletonContext: Skeleton-side Context Prompt Learning for Zero-Shot Skeleton-based Action Recognition
第一作者:王宁(长安大学数据科学与人工智能研究院)
通讯作者:张亮(西安电子科技大学计算机科学与技术学院)
论文概述:针对零样本(Zero-shot)骨骼动作识别中因缺乏环境上下文(如交互物体)导致动作语义模糊、难以区分视觉相似动作的挑战,论文提出了一种基于提示学习的新框架 SkeletonContext。该框架通过引入“跨模态上下文提示模块”,利用大语言模型(LLM)生成的丰富背景语义来补全骨骼动作中的缺失信息,实现了骨骼特征与语言描述的深层语义对齐;同时,结合“关键部位解耦模块”提取运动相关关节特征,进一步增强了在无物体交互场景下对复杂动作的理解能力。在多个主流基准数据集上的实验结果表明,SkeletonContext 在传统及广义零样本任务中均达到了领先水平,显著提升了模型对细粒度动作的推理精度与鲁棒性。
(审稿:李伟 网络编辑:和燕)

